About / Academia / Dry-lab
Overview:
Nobel laureate and biologist Sydney Brenner commented:
Biological research is in crisis, and in Alan Turing’s work there is much to guide us. Technology gives us the tools to analyze organisms at all scales, but we are drowning in a sea of data and thirsting for some theoretical framework with which to understand it.
Out of the ~7000 known rare diseases, only ~6% have existing therapies. It has increasingly become clear that underlying causalities in complex disease has more to do with the interaction of genes rather than one isolated problem in this or that gene. The aim of computational systems biology is to provide a holistic view of biological systems that could address this obstacle.
The overarching goal of my research is to establish sufficient and necessary conditions for observed systems properties and, more importantly, formulate falsifiable hypotheses as to how to “debug” systems aberrations (most notably cancer).
Evolution by Computational Selection:
Joint work [1] [2] with Dr. Waldispühl & Dr. Inoue
| We can represent biological networks as graphs: the nodes are genes, and edges are interactions. An interaction from gene g1 to g2 can be promotional or inhibitory in nature, denoted on this example graph (right) by arrow- or bar-terminated directed edges, respectively. Suppose we are given infallible information from an Oracle that says: g2 and g3 should be promoted, g3 and g7 should be inhibited. We can encode the Oracle opinion as string A as seen on the right. We use "0" to indicate that the Oracle has no opinion on a given gene (note: the Oracle's opinion on g_x is denoted by a_x). The Oracle's opinion simulates evolutionary pressure: it is vital for the organism that this gene should be promoted or inhibited. | nodes = genes edges = interactions 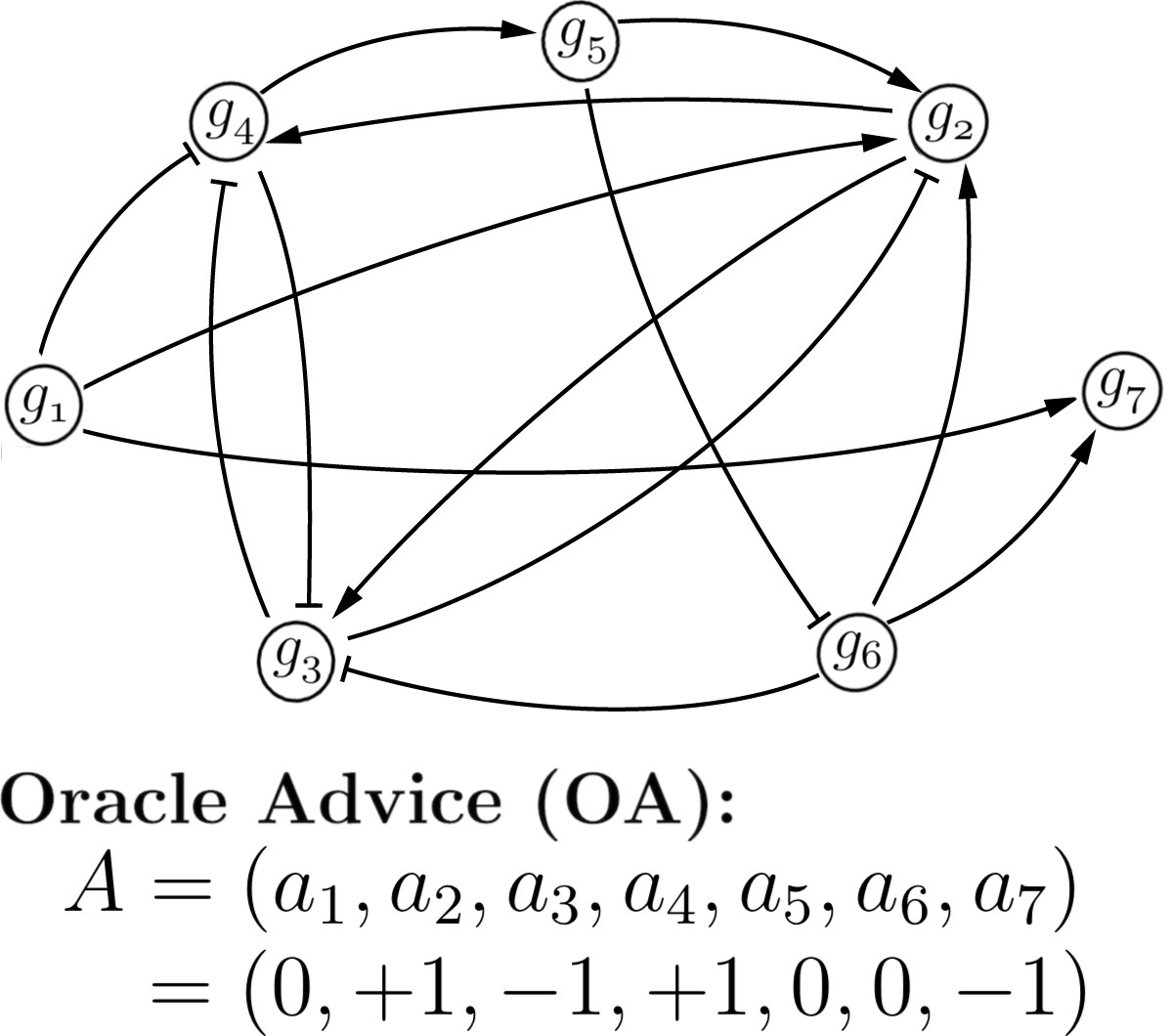 |
| The adjacency matrix M on the right encodes exactly the same information as the graph above: entry in row i column j is non-zero if there exists an interaction between gene i and gene j. The sign of such entry, + or -, indicates whether that interaction is promotional or inhibitory in nature, respectively (corresponding to arrow- or bar-terminated edges in the graph representation above, respectively). The green or red color of a matrix entry indicates whether that interaction supports or undermines the Oracle's opinion on the target gene. For example, the Oracle said gene 2 should be promoted, and gene 1 is doing exactly that (hence green +1 entry in row 1 column 2). But gene 1 is also inhibiting gene 4 which goes against what the Oracle said about g 4 (see above graph, a4 = +1), hence the red-colored entry -1 in row 1 column 4. Gene 1 is also promoting gene 7, while the Oracle said gene 7 should in fact be inhibited. | 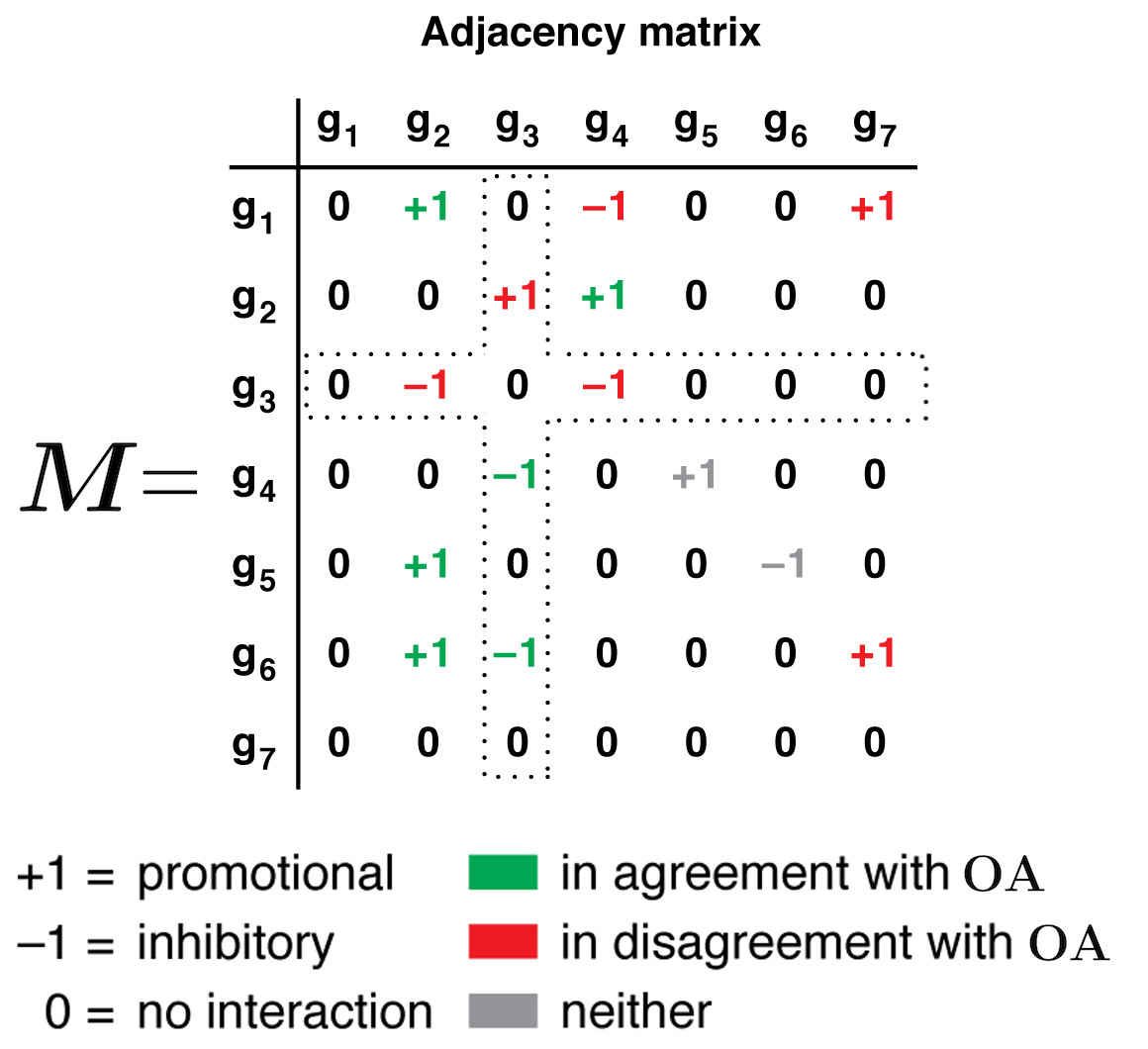 |
| We score the genes based how many beneficial (green) or detrimental (red) interactions they're engaged in, whether exerting or receiving them. The benefit and damage score of gene i is the sum of green and red entries, respectively, along row and column i (see the dotted row/column 3 in the previous figure, and the dotted row 3 in the scoreboard on the right). A beneficial or detrimental interactions factors in the scores of both the source and target genes of said interaction. Given this score boards, what is the ideal evolutionary path for the organism? What gene(s) should ideally be mutated/deleted in the next generations and which should be conserved as is, such that the total number of damaging interactions network-wide is kept to some tolerable threshold? This is the core optimization question that we study, we refer to it as the network evolution problem (NEP). Particularly, we ask: have the topological features of biological networks emerged in order to effectively minimize the computational cost of finding acceptably optimal solutions to this problem? | 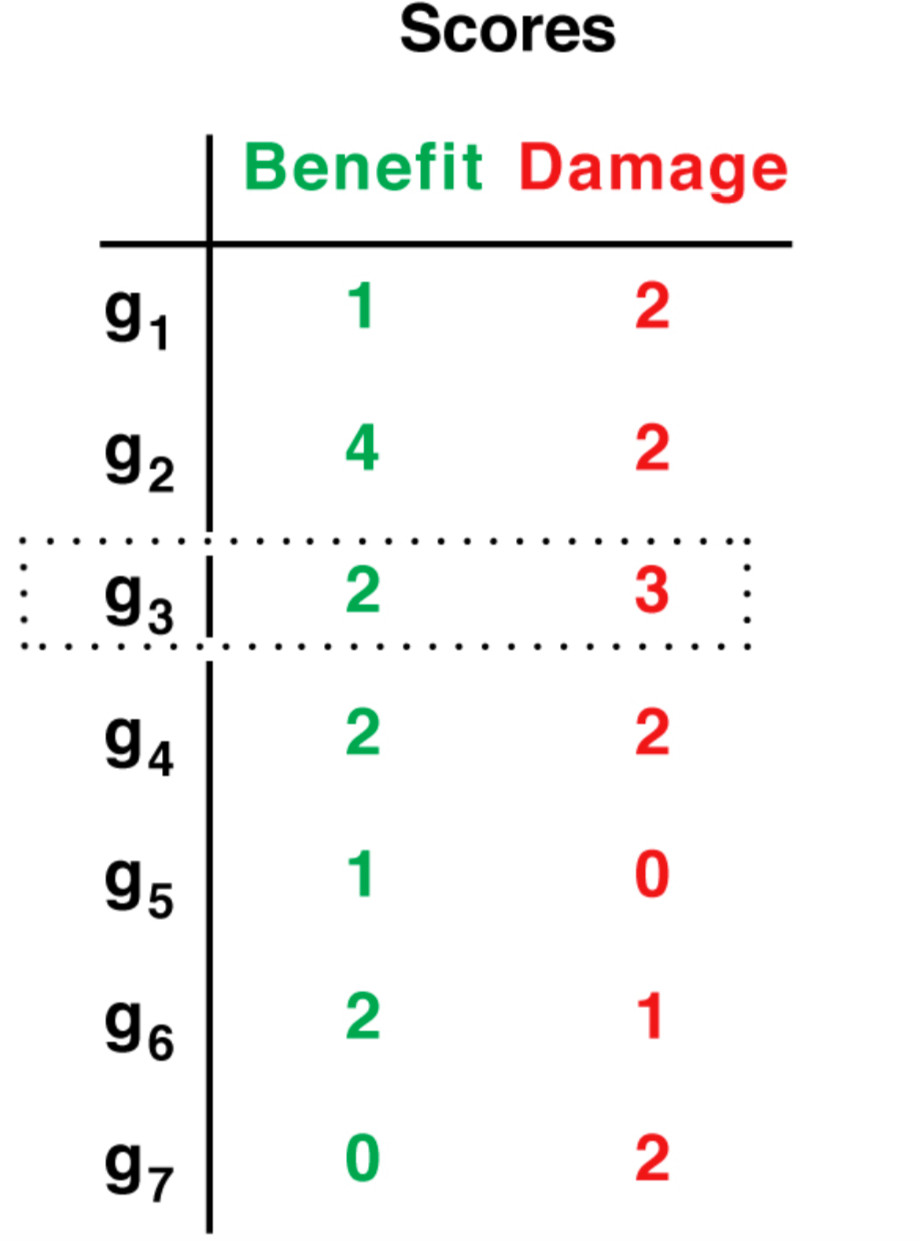 |
| What is the evolutionary cost of finding acceptable solutions to NEP? How many generations of random-variation non-random selection (RVnRS) would it take before just the right set of genes have been mutated advantageously, moving the network away from a deleterious and into and advantageous state (one where the total number of Oracle-contradicting damaging interactions are under a tolerable threshold)? The well-known knapsack optimization problem (KOP) is reducible to NEP and as such the latter belongs to the same computational complexity class ("difficulty") as the former. More concretely, any KOP instance can be turned into a corresponding (fictional) biological network under stress, i.e. an NEP instance. The hypothetical stressed network discussed above is in fact a mirror of the KOP instance on the right figure (objects = genes, values/weights = benefits/damages). The laptop for example corresponds to gene 2. Therefore, this evolutionary optimization problem is at least as hard as the knapsack problem. KOP is in practice an easy problem to solve, and there exist fairly satisfactory approximation algorithms. That is, of course, if one is at liberty to choose an algorithm. In evolutionary context, however, the only available algorithm is RVnRS, and therefore computational difficulty of NEP must be measured against it. | 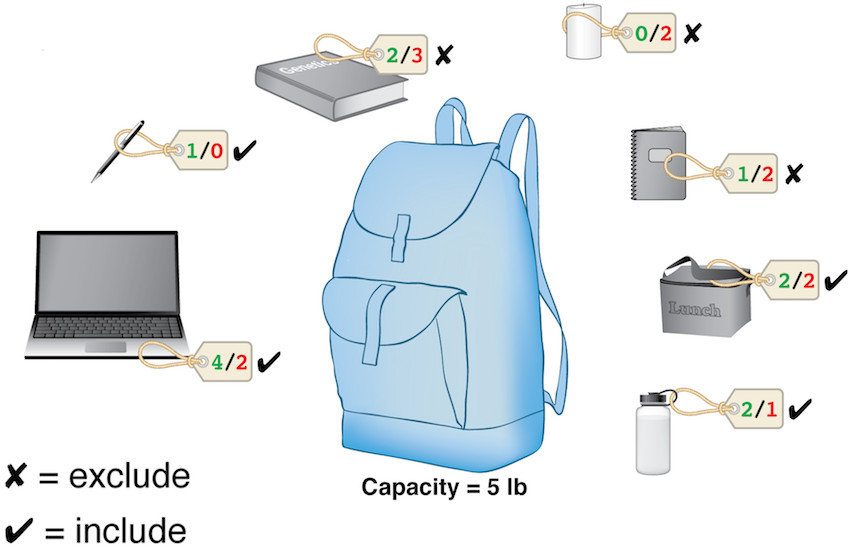 |
| Semantically, NEP can be interpreted in the context of regulation: what genes should ideally be promoted and which inhibited, such that the total number of damaging interactions (in light of some evolutionary pressure) is minimal to a threshold? The above hypothetical network therefore can be considered as one representing the interaction network of co-expressed genes in the cytoplasm as depicted the right figure. | 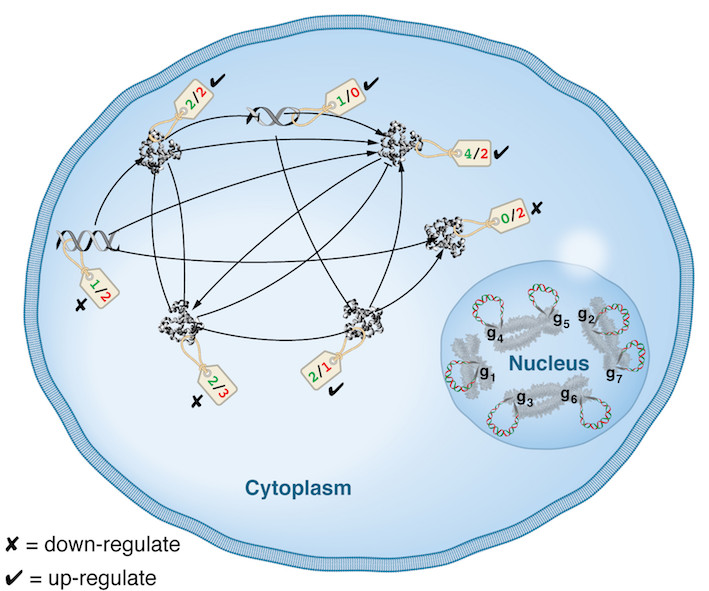 |
| Alternatively, and without syntactic modifications, NEP can also be interpreted as: which genes should be mutated/deleted and which conserved such that the total number of damaging interactions (in light of some evolutionary pressure) is minimal to a threshold? | 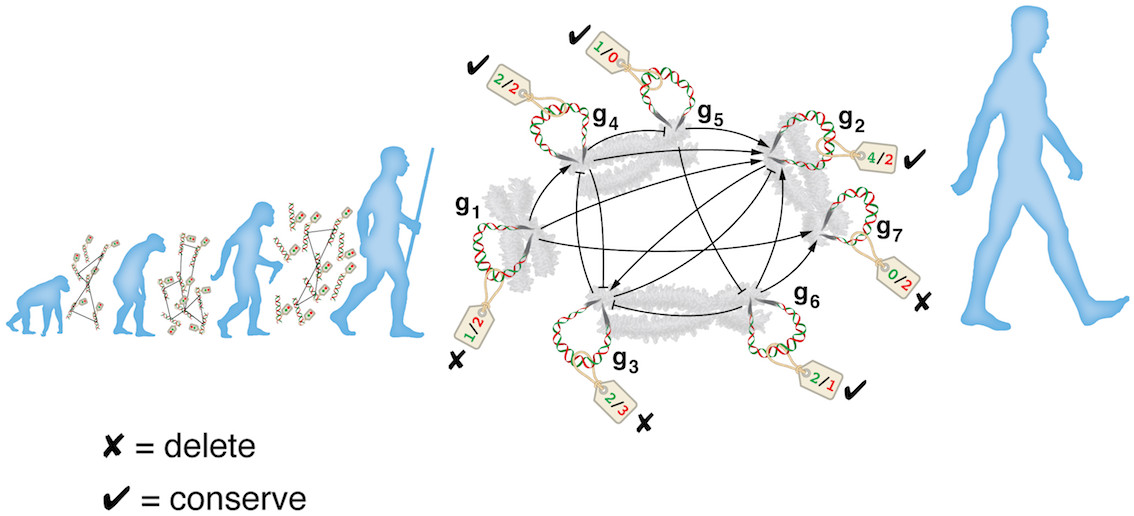 |