About / Academia / Wet-lab
Overview:
The resilient and ancient deoxyribonucleic acid (DNA) encodes the blueprint of the machinery of life. But it has in recent decades attracted interest for material purposes.
In one avenue of research, DNA has proven to be a sturdy and, more importantly, programmable substrate with which intricate 2D and 3D nano-structures can be fabricated, with exciting potential usecases.
In another avenue, DNA has been used as a computational medium. Adleman kicked off this line of this research with an insightful demonstration of a DNA-based computation of an instance of the NP-Complete Hamiltonian Path Problem (HPP), inspiring many subsequent demonstrations.
Below is a brief about my own work in both avenues.
DNA Knitting:
Joint work with Dr. Waldispühl & Dr. Vidal
“Knitting” because the basic principle is that different nano-structures can be “knitted” (or carved out) from the same template. Other aims of this method: 1) no viral scaffolding DNA involved (hence, no regulatory and lower fabrication cost), 2) maximum resolution (a pixel = one base-pair), and 3) PCR-driven (no chemical synthesis except for primers).
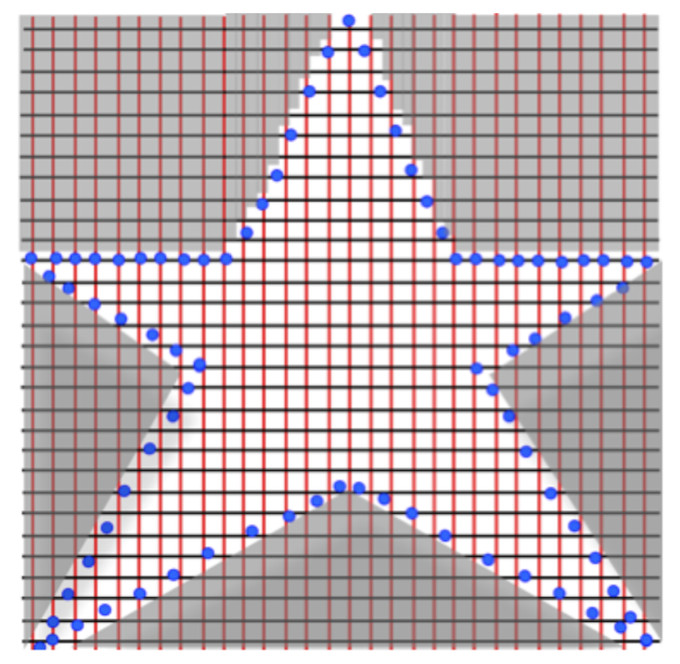 | Programmability in DNA knitting method. Given a DNA lattice as template, segments (light area) of the horizontal (black) and vertical (red) DNA strands can be carved using PCR, effectively fabricating of nano-structures of interest ("programmability"). The choice of primer oligonucleotides (blue dots) determines the resulting nano-shape (primers ~ program arguments). Regions falling outside the range a given pair of primers are effectively “amplified-out”. Full report .. |
These slides provide an overview of the method, for full details see this report. The inspiration for this method originated from a DNA-based computation of an instance of the NP-complete edge-matching puzzles.
DNA/RNA Computing:
Joint work with Dr. Major & Dr. Waldispühl
Subsequent to Adleman’s insightful demonstration of a DNA-based method to encode and solve an instance of the NP-complete Hamiltonian Path Problem, it was realized that, while its “bit” is extremely tiny compared those in silicon-based computers, DNA will not push the limits of what can be solved practically.
The inherent intractability of NP-Complete problems still manifests in DNA computing manifests itself by requiring an exponential molar amount of DNA strands to guarantee a successful computation, analogous to how in-silico NPC algorithms require CPU/memory resources that are exponential in problem size. To solve a 200-node HPP instance following Adleman’s method, for example, would require an amount of raw DNA that is greater than Earth in mass (Hartmanis, Juris. “On the weight of computations.” EATCS Bulletin 55 (1995): 136-138. See also p. 70, lower paragraph, in this thesis and section 1.4 in this thesis).
Nonetheless, bringing a computational perspective to a soup of interacting bio-molecules inspired many computer scientists to bring their theory into the cell (notice how this paradigm is the inverse of bioinformatics, in which the cell is “taken to the computer”).
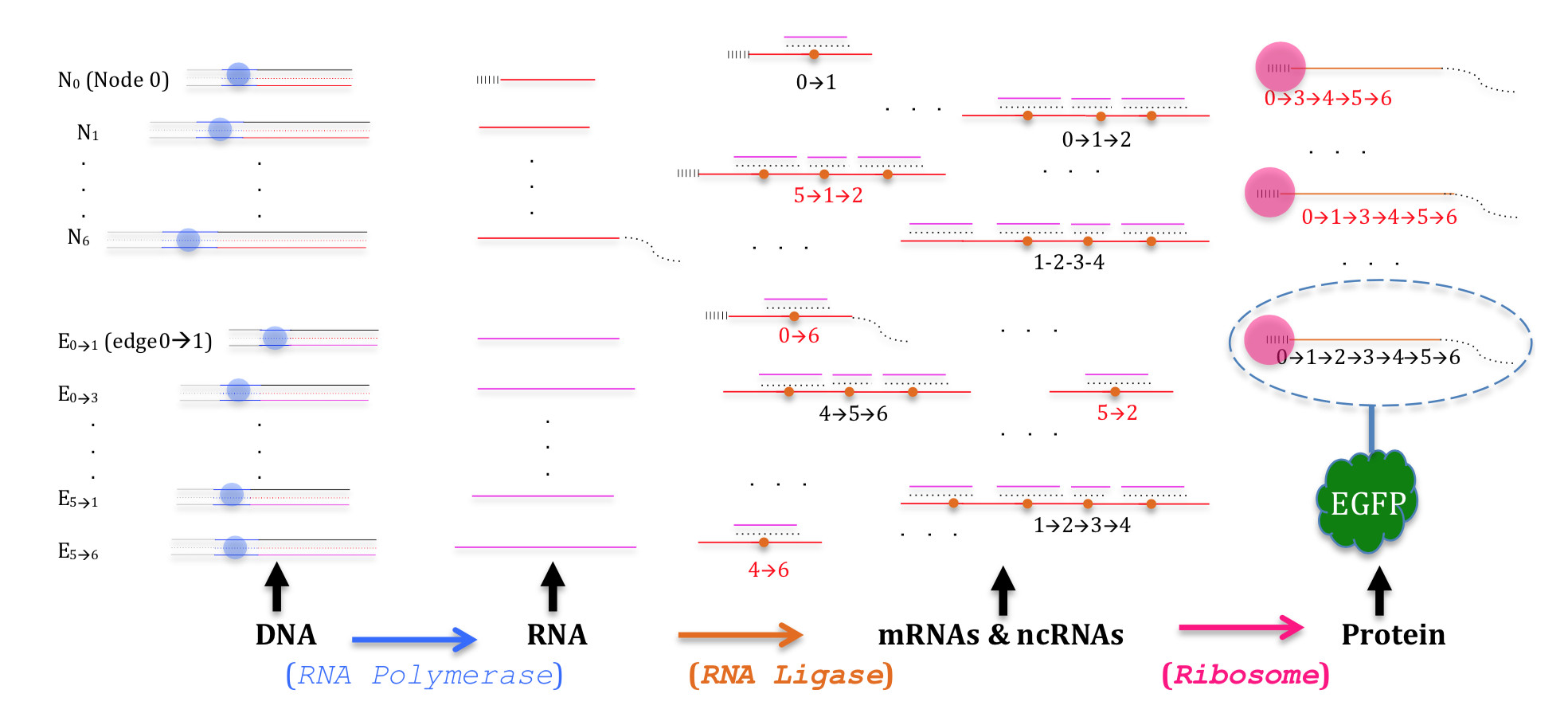 |
| A DNA/RNA/Protein-based HPP solution that mimics the functioning of the cell: left to right: dsDNA templates for each node & edge in A-HPP, each template primed with leading (grey) sequence and T7 promoter (blue) sequence. T7 polymerase (blue circle) transcribes an RNA strand from each DNA template (orange lines for nodes; purple for edges), N0’s sequence is primed with m7G analog (NEB) and contains a leading ribosome-binding site (black vertical bars), N0’s transcript is polyadenylated (curvy dotted line) with E. coli poly(A) (NEB). RNA transcripts are ligated with T4 RNA ligase 2 (NEB) (orange circles) leading a brute-force exhaustive generation of correct and erroneous paths (black & red subscripts, respectively). Ligated sequences beginning with N0 and ending with N6 represent mRNAs suitable for translation by the ribosome (by virtue of m7G cap & RBS for translation initiation in N0, and poly(a) tail for mRNA stability in N6), but only the correct path encodes the EGFP protein (by deliberate design); since nodes’ sequences have different lengths, the correct solution’s protein has a unique kD weight; correctness of node sequence in the solution path is validated by the fluorescence of EGFP. Full report .. |